AWS ECS deployments step-by-step

The default ECS deployment type is called rolling update. With this simple approach, running ECS tasks are replaced with new ECS tasks.
You control this process with the deployment configuration, where you define the minimum and maximum number of tasks allowed during a deployment. Through this mechanism you can ensure enough tasks are running to service your traffic, and likewise you're not overspending by running too many.
To understand the deployment process we'll take the following simple setup as an example.
-
ECS service - with a desired count of 1, the service tries to make sure one ECS task is running at a time
-
Load balancer - in this case we're using an Application Load Balancer (ALB), which receives user requests through a load balancer listener
-
Target group - connected to the load balancer listener, the target group contains target IP addresses across which incoming traffic is distributed
-
Target - automatically created by the ECS service, the target references the private IP of the ECS task
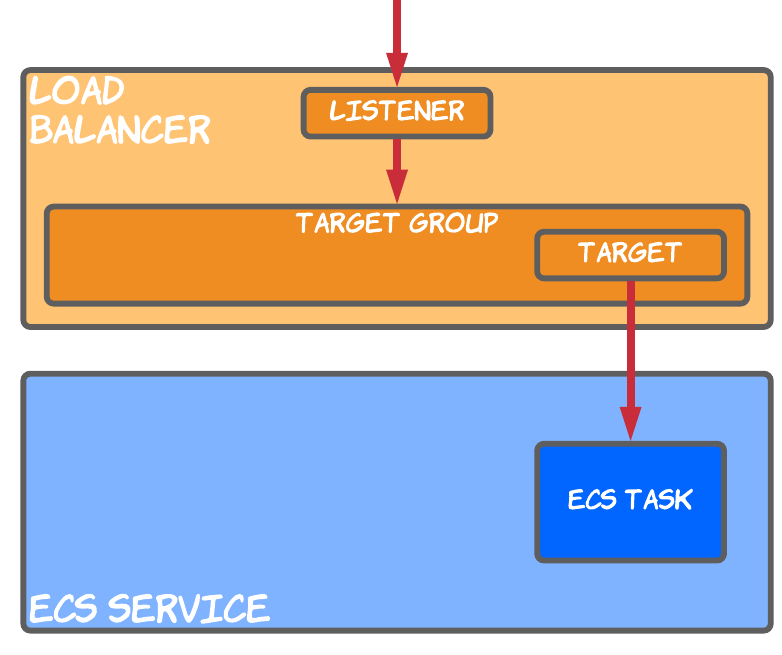
For this setup, let's have a look at how it looks in the AWS Console.
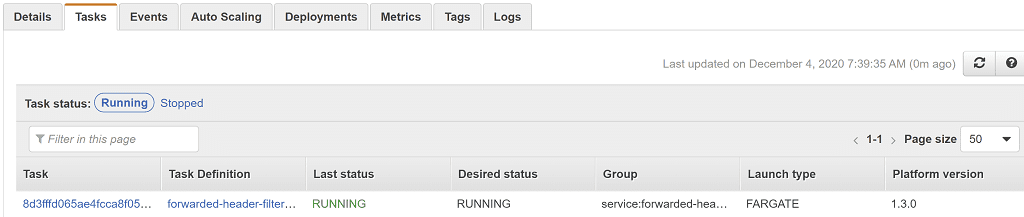
Going to Services > Elastic Container Service > Clusters, clicking on the cluster name, clicking on the service, then selecting the Tasks tab shows us we have a single ECS task running.
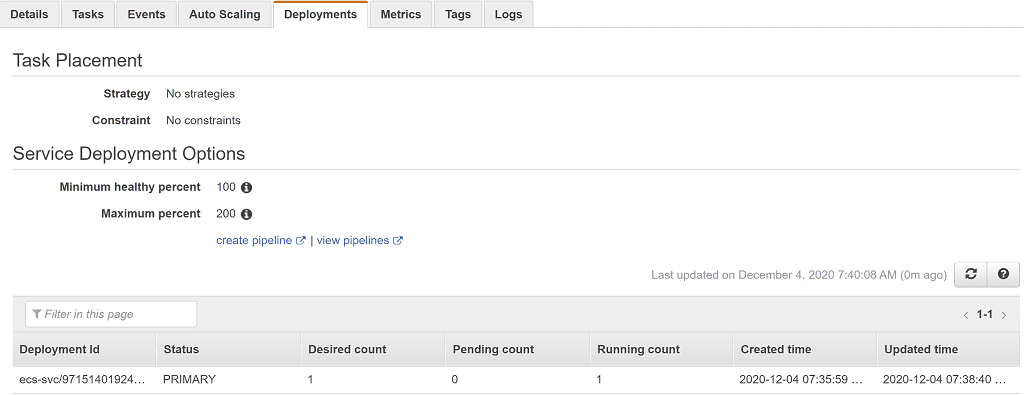
The Deployments tab shows us the status of any ongoing deployments. We have a single deployment listed in the PRIMARY status, meaning this is the most recent deployment. No other records means there is no ongoing deployment.
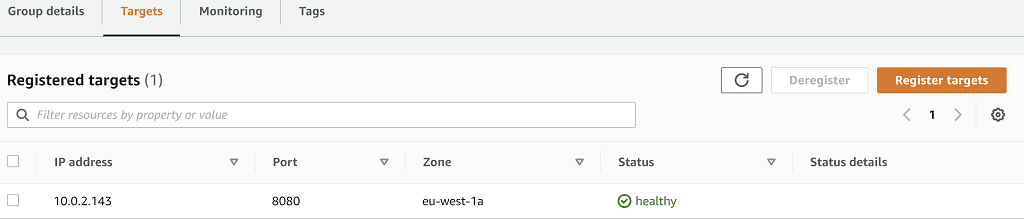
Lastly, let's go to Services > EC2 > Target Groups, then select the target group relevant to this service. Selecting the Targets tab shows us we have a single registered target in the healthy status, pointing at our running ECS task.
At each step through the deployment process covered in the rest of this article, we'll evaluate the state of each these resources.
Default deployment configuration: for this example we'll use the default deployment configuration, which allows a maximum of 2 tasks (200% of the service's desired count) and a minimum of 1 task (100% of the desired count). This means during deployment a new task will be created before the old one is terminated.
Now we're going to step through the five steps of the ECS deployment process for the rolling update deployment. If you want to follow along with this article, feel free to create the same setup in your own account using the CloudFormation described in the Try it out yourself section.
1) Initiate deployment
In a scenario where you want to deploy a new version of an ECS, task you'll need to initiate a deployment. This might be through CloudFormation, Terraform, the AWS CLI, or AWS Console.
One way to do this is to issue this AWS CLI command, which starts a deployment even if there are no changes to make.
aws ecs update-service --service <service-name> --cluster <cluster-name> --force-new-deployment
Whatever method is used, we'll end up in a situation where a deployment is initiated in ECS. Note this is the only manual step, with everything from this point onwards being managed automatically by AWS.
Now the Deployments tab shows a new deployment in the PRIMARY state. You can see it has a desired count of 1 task, but a running count of 0 because the task hasn't started yet.

The deployment we saw before has moved to the ACTIVE state, which means it still has tasks running (1 task), but is in the process of being replaced by a new PRIMARY deployment.
2) Start new ECS task
Now on the Tasks tab we have a new ECS task in the PROVISIONING state. This is the stage where setup happens like creating an elastic network interface.

Shortly afterwards the task moves to the PENDING status, where the container agent is doing things like pulling the Docker image from the repository.

Last, the task moves into the RUNNING status, which means the Docker image has started.

This doesn't necessarily mean the new task is ready to receive traffic, as the application running inside may have a startup sequence to run.
At this point we have two tasks running, one from each deployment.
Even though the new task is in a RUNNING state, there's no way to make requests to it until it's been registered into the load balancer.
3) Register load balancer target
Back in the list of target group targets, we now have two targets. The first is for the old ECS task, and the second for the new task. The initial state means the load balancer is registering the target and performing initial health checks.

Since the application running in the ECS task may not immediately be ready to serve traffic, it may take some time to return a successful health check result and move to the healthy status
4) Drain load balancer target
Once the new target gets a successful health check response it's marked as healthy and it will start receiving user requests. The target to be replaced goes into a draining state.

When the target is draining it's in the process of being deregistered from the target group, which means:
-
no more requests will be sent to the target
-
any in-flight requests can be completed, as long as it's done within the target group's deregistration delay period (more on this later)
At this point we still have two registered targets in the target group, only one of which is receiving new requests.
Once the deregistration delay has elapsed though, the old target is removed from the target group entirely. All traffic is now being served by the new target.

5) Stop ECS Task
At this stage, we have an ECS task that has been deregistered from the load balancer, but is still running. ECS will now schedule the deletion of the old ECS task, following this procedure:
-
a
SIGTERMsignal is sent to any containers in the ECS task to tell them to shut down (remember an ECS task can have multiple containers). This is the equivalent of runningdocker stop <container-id>against a Docker container. Just like with Docker, the ECS task has a default timeout of 30s in which to terminate (more on this later). -
If the ECS task has not gracefully shutdown by the end of the stop timeout, it will be forcefully killed with the
SIGKILLsignal.
At this point we have a single ECS task running.

And in the Deployments tab we have a single deployment listed in the PRIMARY status, indicating we have no ongoing deployment.

Awesome! We've successfully reached our desired state of a single newly deployed ECS task, receiving requests through the load balancer.
ECS deployment timeouts
During the deployment process above there were two timeouts mentioned that are crucial to ensure:
-
your users receive a seamless uninterrupted experience during deployment
-
your deployments happen as quickly as possible
Deregistration delay
In deployment step 4 above, ECS initiates the deregistration of the ECS task from the load balancer target group. In order to ensure that any in-flight requests can be serviced without interruption, the target group waits for the configured deregistration delay before removing the target.
During the deregistration process:
-
any in-flight requests can continue to receive traffic
-
no new connections are established to the target being deregistered
The deregistration delay is configured on a target group, with a default of 300 seconds (5 minutes). You can view and edit the value for a target group in the Group details tab.
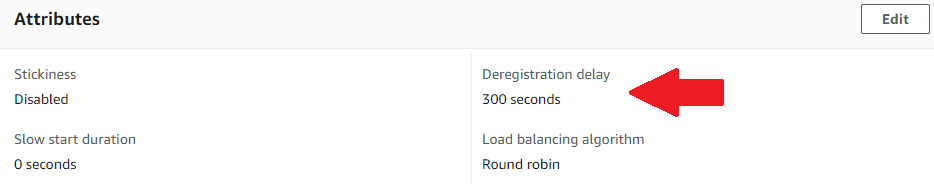
It's worth noting that even if there are no in-flight requests, the load balancer will wait for the full deregistration delay before removing the target. This can make deployments unnecessarily slow, especially if you have an ECS task that doesn't have any long running requests.
Consider reducing the deregistration delay to speed up deployments of ECS services that have short-lived requests.
Stop timeout
Once the ECS task has been deregistered from the target group, ECS still needs to stop it. This process begins by sending any containers running in the task the SIGTERM signal, giving them a chance to begin shutting down gracefully. By default, a container has 30 seconds to complete any shutdown logic, before the SIGKILL signal is sent to it, forcefully killing it.
You can see the configured stop timeout for a container in the container definition within the task definition (see Services > Elastic Container Service > Task Definitions).
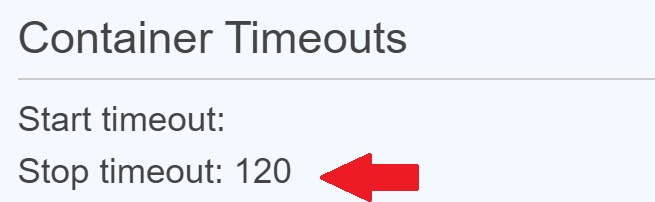
Depending on which launch type you're using for your ECS task, the stop timeout can have a maximum value of:
-
120 seconds for the Fargate launch type
-
no maximum for the EC2 launch type
If your ECS service has any long running requests or background processes, consider increasing the stop timeout.
Try it out yourself
To familiarise yourself with the ECS deployment process and its parameters I suggest creating your own deployment. You can then modify the parameters described above and see how the behaviour changes.
To get going with an example quickly, here's a simple CloudFormation template I've created for you which creates:
-
a VPC and subnets
-
an ECS task definition for using the NGINX container (a simple container that returns a default response on port 80)
-
an ECS service with a desired count of 1
-
a load balancer and configuration to integrate the ECS service with it

The launch stack button above will open the create stack page in your own AWS account. Just agree to the additional capabilities and click Create stack. After 5 minutes the stack should reach the CREATE_COMPLETE status.
Now you can go to Services > EC2 > Load balancers, click on the newly created load balancer, and copy the DNS name. Paste this into a browser and you'll get the default Welcome to nginx! response. If you see this, you know everything's working correctly
Initiate an ECS deployment with:
aws ecs update-service --service <service-name> --cluster default-cluster --force-new-deployment
Using the service name which you can get from Services > Elastic Container Service > Clusters > default-cluster. Watch the deployment process described in this article yourself, through the AWS Console.
Don't forget to delete the CloudFormation stack when you're done to avoid any unnecessary charges.
Resources
-
Check out these AWS docs describing the load balancer deregistration delay
-
In the docs Task definition parameters there's more info on the task stop timeout
If this is a problem you're dealing with in your own team, you can see how I approach software delivery in practice.